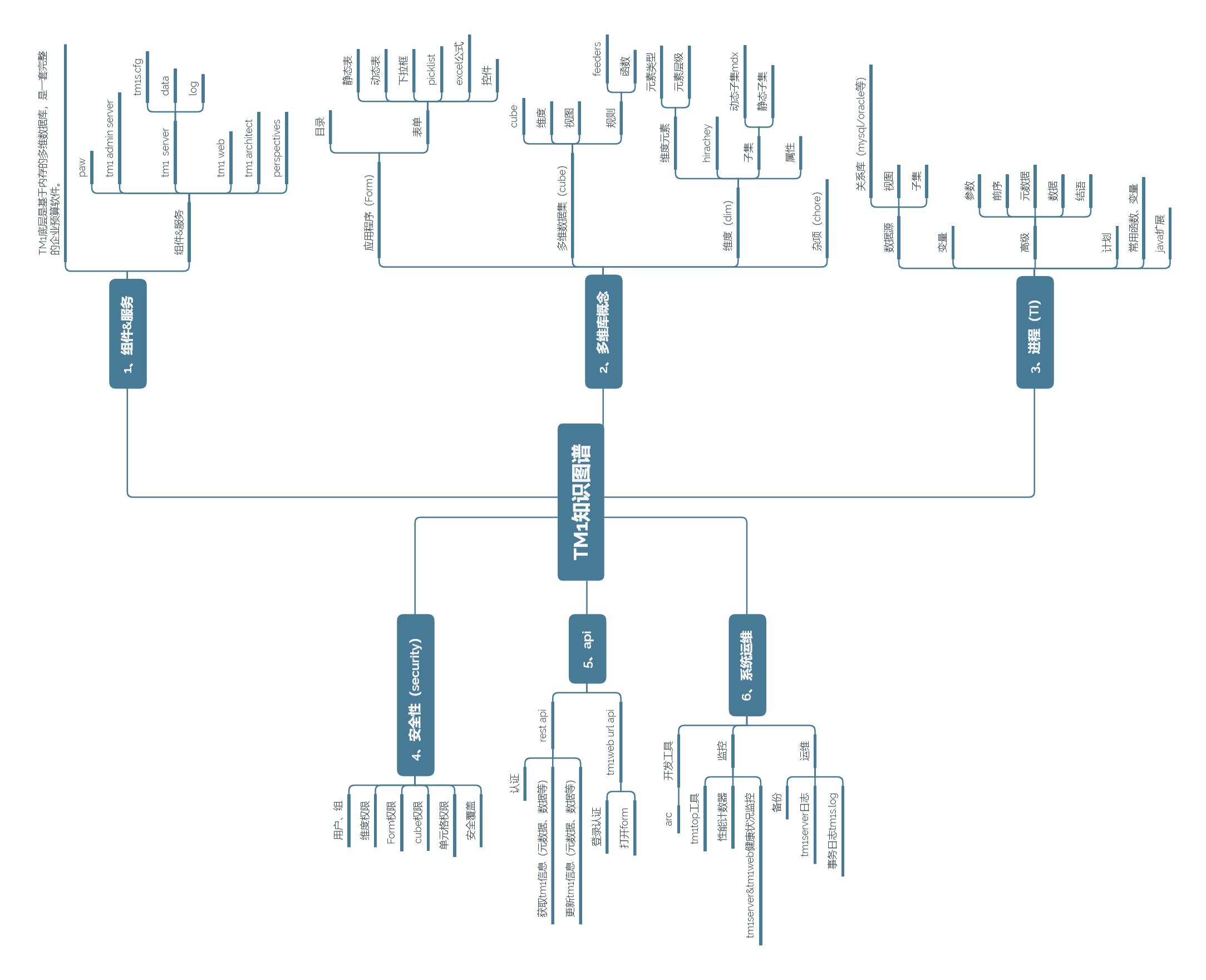
思维导图截图:
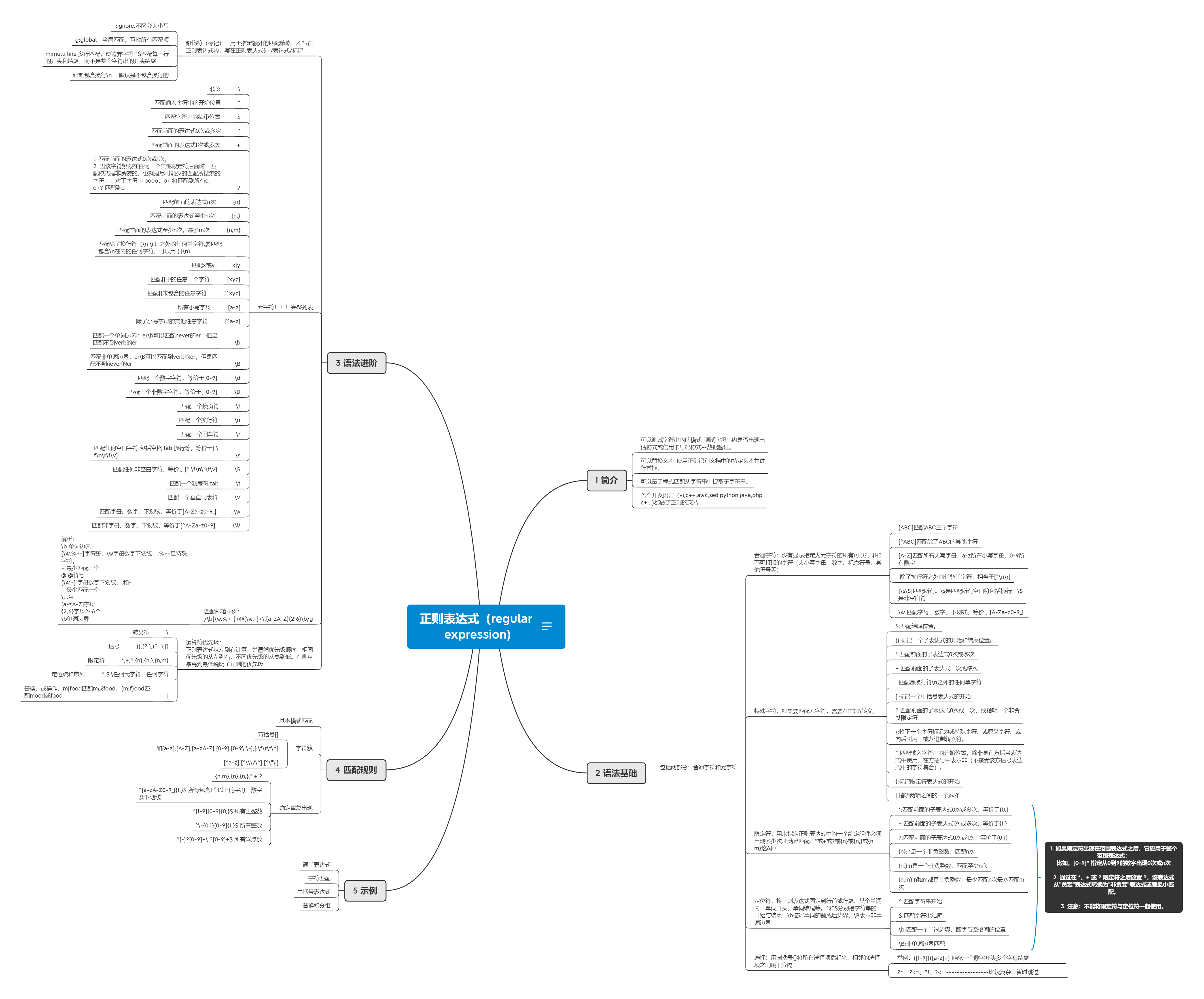
# 正则表达式(regular expression)
正则表达式,包括普通字符和特殊字符(元字符)。
## 1 简介
### 可以测试字符串内的模式-测试字符串内是否出现电话模式或信用卡号码模式--数据验证。
### 可以替换文本-使用正则识别文档中的特定文本并进行替换。
### 可以基于模式匹配从字符串中提取子字符串。
### 各个开发语言(vi,c++,awk,sed,python,java,php,c+...)都做了正则的支持
## 2 语法基础
### 包括两部分:普通字符和元字符
- 普通字符:没有显示指定为元字符的所有可以打印和不可打印的字符(大小写字母、数字、标点符号、其他符号等)
- [ABC]匹配ABC三个字符
- [^ABC]匹配除了ABC的其他字符
- [A-Z]匹配所有大写字母,a-z所有小写字母,0-9所有数字
- .除了换行符之外的任务单字符,相当于[^\n\r]
- [\s\S]匹配所有。\s是匹配所有空白符包括换行,\S是非空白符
- \w 匹配字母、数字、下划线,等价于[A-Za-z0-9_]
- 特殊字符:如果要匹配元字符,需要在前加\转义。
- $:匹配结尾位置。
- ():标记一个子表达式的开始和结束位置。
- *:匹配前面的子表达式0次或多次
- +:匹配前面的子表达式一次或多次
- .:匹配除换行符\n之外的任何单字符
- [:标记一个中括号表达式的开始
- ?:匹配前面的子表达式0次或一次,或指明一个非贪婪限定符。
- \:将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。
- ^:匹配输入字符串的开始位置,除非是在方括号表达式中使用,在方括号中表示非(不接受该方括号表达式中的字符集合)。
- {:标记限定符表达式的开始
- |:指明两项之间的一个选择
- 限定符:用来指定正则表达式中的一个给定组件必须出现多少次才满足匹配:*或+或?或{n}或{n,}或{n,m}这6种
- *:匹配前面的子表达式0次或多次,等价于{0,}
- +:匹配前面的子表达式1次或多次,等价于{1,}
- ?:匹配前面的子表达式0次或1次,等价于{0,1}
- {n}:n是一个非负整数,匹配n次
- {n,}:n是一个非负整数,匹配至少n次
- {n,m}:n和m都是非负整数,最少匹配n次最多匹配m次
- 定位符:将正则表达式固定到行首或行尾、某个单词内、单词开头、单词结尾等。^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界
- ^:匹配字符串开始
- $:匹配字符串结尾
- \b:匹配一个单词边界,即字与空格间的位置
- \B:非单词边界匹配
- 选择:用圆括号()将所有选择项括起来,相邻的选择项之间用 | 分隔
- 举例:([1-9])([a-z]+) 匹配一个数字开头多个字母结尾
- ?=、?<=、?!、?<! ----------------比较复杂,暂时跳过
## 5 示例
### 简单表达式
### 字符匹配
### 中括号表达式
### 替换和分组
## 4 匹配规则
### 基本模式匹配
### 字符簇
- 方括号[]
- 如[a-z],[A-Z],[a-zA-Z],[0-9],[0-9\.\-],[ \f\r\t\n]
- [^a-z],[^\\\/\^],[^\"\']
### 确定重复出现
- {n,m},{n},{n,},*,+,?
- ^[a-zA-Z0-9_]{1,}$ 所有包含1个以上的字母、数字及下划线
- ^[1-9][0-9]{0,}$ 所有正整数
- ^\-{0,1}[0-9]{1,}$ 所有整数
- ^[-]?[0-9]+\.?[0-9]+$ 所有浮点数
## 3 语法进阶
### 修饰符(标记):用于指定额外的匹配策略,不写在正则表达式内,写在正则表达式外 /表达式/标记
- i:ignore,不区分大小写
- g:global,全局匹配,查找所有匹配项
- m:multi line,多行匹配,使边界字符 ^$匹配每一行的开头和结尾,而不是整个字符串的开头结尾
- s:使.包含换行\n,.默认是不包含换行的
### 元字符!!!完整列表
- \
- 转义
- ^
- 匹配输入字符串的开始位置
- $
- 匹配字符串的结束位置
- *
- 匹配前面的表达式0次或多次
- +
- 匹配前面的表达式1次或多次
- ?
- 1. 匹配前面的表达式0次或1次;
2. 当该字符紧跟在任何一个其他限定符后面时,匹配模式是非贪婪的,也就是尽可能少的匹配所搜索的字符串:对于字符串 oooo,o+ 将匹配到所有o,o+? 匹配到o
- {n}
- 匹配前面的表达式n次
- {n,}
- 匹配前面的表达式至少n次
- {n,m}
- 匹配前面的表达式至少n次,最多m次
- .
- 匹配除了换行符(\n \r)之外的任何单字符,要匹配包含\n在内的任何字符,可以用 (.|\n)
- x|y
- 匹配x或y
- [xyz]
- 匹配[]中的任意一个字符
- [^xyz]
- 匹配[]未包含的任意字符
- [a-z]
- 所有小写字母
- [^a-z]
- 除了小写字母的其他任意字符
- \b
- 匹配一个单词边界:er\b可以匹配never的er,但是匹配不到verb的er
- \B
- 匹配非单词边界:er\B可以匹配到verb的er,但是匹配不到never的er
- \d
- 匹配一个数字字符,等价于[0-9]
- \D
- 匹配一个非数字字符,等价于[^0-9]
- \f
- 匹配一个换页符
- \n
- 匹配一个换行符
- \r
- 匹配一个回车符
- \s
- 匹配任何空白字符 包括空格 tab 换行等,等价于[ \f\n\r\t\v]
- \S
- 匹配任何非空白字符,等价于[^ \f\n\r\t\v]
- \t
- 匹配一个制表符 tab
- \v
- 匹配一个垂直制表符
- \w
- 匹配字母、数字、下划线,等价于[A-Za-z0-9_]
- \W
- 匹配非字母、数字、下划线,等价于[^A-Za-z0-9]
### 匹配邮箱示例:
/\b[\w.%+-]+@[\w.-]+\.[a-zA-Z]{2,6}\b/g
- 解析:
\b 单词边界;
[\w.%+-]字符集,\w字母数字下划线,.%+-是特殊字符;
+ 最少匹配一个
@ @符号
[\w.-] 字母数字下划线,.和-
+ 最少匹配一个
\. .号
[a-zA-Z]字母
{2,6}字母2~6个
\b单词边界
### 运算符优先级:
正则表达式从左到右计算,并遵循优先级顺序。相同优先级的从左到右,不同优先级的从高到低。右侧从最高到最低说明了正则的优先级
- \
- 转义符
- (),(?:),(?=),[]
- 括号
- *,+,?,{n},{n,},{n,m}
- 限定符
- ^,$,\任何元字符、任何字符
- 定位点和序列
- |
- 替换,或操作,m|food匹配m或food,(m|f)ood匹配mood或food